CaseForge
A multi-agent pipeline that generates structured test suites for AI agents, with human review checkpoints built into the workflow.

Built during the AI for Good Hackathon at Aalto AI, CaseForge is a weekend MVP for generating curated test suites for AI agents through a multi-agent pipeline with human review built in.
Context
As more teams ship AI agents into production, the tooling for building those agents has matured faster than the tooling for testing them well. Existing eval platforms are strong at tracing, benchmarking, and monitoring, but they usually assume a test suite already exists.
CaseForge was built around that gap: the hard part for many small teams is not only running evaluations, but deciding what to test in the first place.
Problem
Agent evaluation is difficult because the system under test is not deterministic in the way traditional software is. Outputs vary, tasks are open-ended, and failure can show up in many forms: weak reasoning, poor tool use, unfair responses, brittle edge-case handling, or unsafe behavior.
For a solo developer or small team without a QA function, the default testing process is often informal: try a few prompts, think of a few edge cases, and ship. That is fast, but it does not create systematic coverage.
Solution

CaseForge helps developers generate a structured test suite for an AI agent. The workflow combines AI-generated breadth with human judgment at two key points.
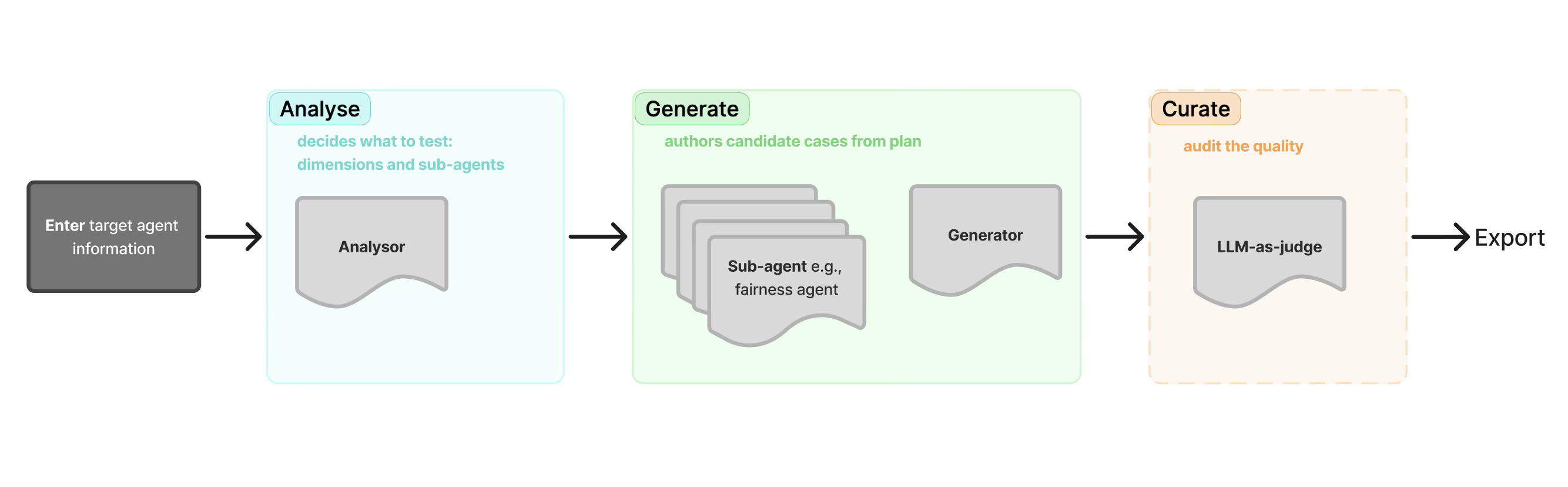
The pipeline works in five stages:
- describe the target agent and its intended behavior
- analyze the agent and propose evaluation dimensions and failure modes
- generate test materials through specialist sub-agents working in parallel
- curate and rank the resulting cases
- export a finalized test suite for downstream evaluation
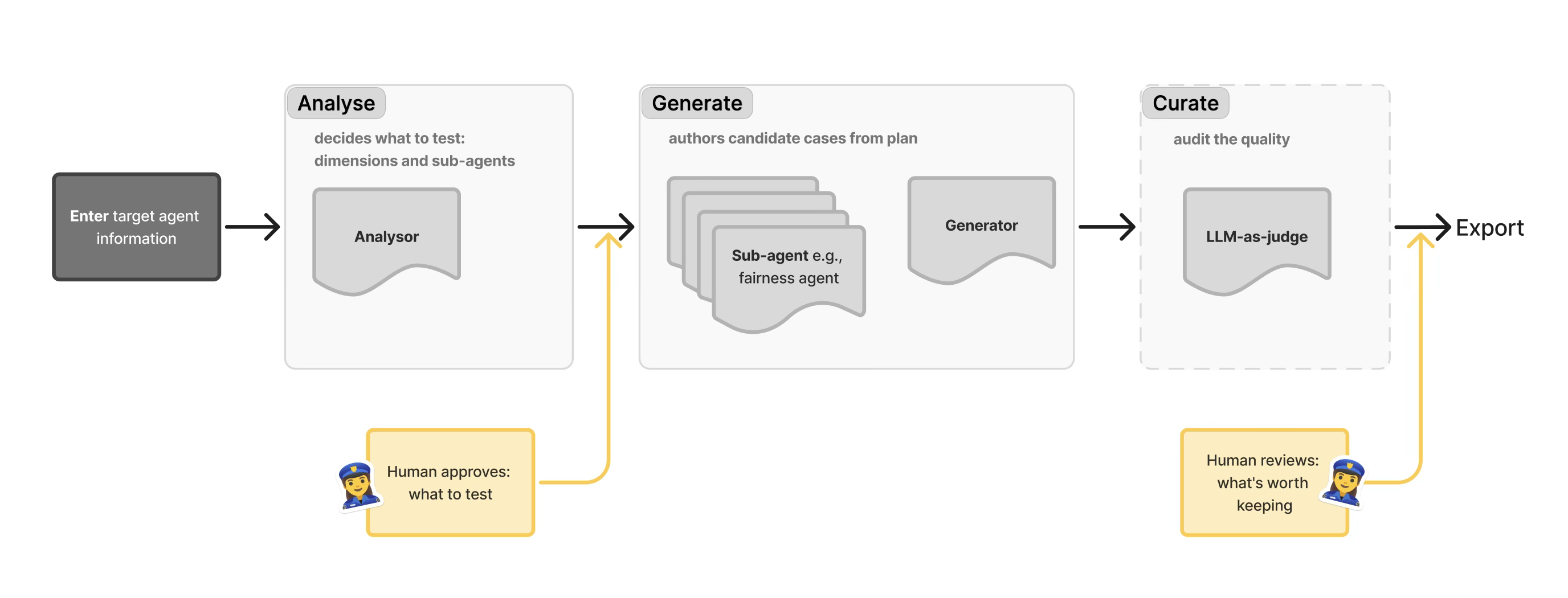
Two human-in-the-loop checkpoints were designed into the system on purpose:
- one after analysis, to confirm what should be tested
- one after case generation, to decide what should be kept
That structure reflects a core product belief: developers still need to own judgment about scope and quality, even if AI helps author the material.
How the system works
Key design decisions
- I chose a multi-agent structure instead of a single “generate N test cases” prompt because specialized roles create more transparent and more diverse coverage.
- I kept two explicit human review checkpoints because deciding what matters and what is worth keeping still requires domain judgment.
- I added a curator layer because reviewing a large raw case set without ranking creates too much cognitive load.
- I treated fairness and adversarial testing as default evaluation dimensions rather than optional extras, in line with the hackathon’s responsible AI theme.
Outcome
The MVP was demonstrated live at the hackathon using an Email Draft Assistant as the target agent. The demo showed the full flow from agent description to curated test suite and made the product concept concrete enough to pitch to Microsoft engineer judges.
The result was not a finished product, but a credible proof that the workflow is coherent, technically feasible, and worth exploring further.
Limitations
This is still an early MVP. Prompt quality has not been systematically validated across many agent types, downstream integrations with evaluation harnesses are not yet built, and the system currently treats test-suite generation as a one-time workflow rather than a recurring lifecycle.
What I learned
This project clarified how much of AI product quality depends on the layer before evaluation even starts. The blank-page problem in testing is real, and solving it requires both system design and product judgment. It also reinforced that responsible AI becomes much more practical when fairness, adversarial thinking, and review checkpoints are built into the workflow from the beginning instead of added later.
Tools & Methods
Let's talk
Working on something complex?
Good judgment, real problem, difficult environment — I'd like to hear about it.